Currywurst is not made of steel and vice versa.
There seems to be a controversy about when to add cardinalities to (class) diagrams and when not.
The answer is, as always: it depends.
The purpose of the diagram is what counts, so apply separation of concerns in the diagrams
you make in analysis and design too.
That does not mean that analysis is about data, and design is about the software system, but that the
aspect you are dealing with in your model will decide what kind of information is needed in a diagram.
The purpose of modeling is communication
A model in any form is a simplification of reality. Model is the art of leaving out details that are not relevant. Not relevant for the purpose of the model. Modeling in this sense also implies that there can be more models of the same reality. Each of these models can then highlight different aspects of interest for what you want to communicate. You want to express these aspects to communicate a meaning, relation, dependency, composition etcetera. A model is always about abstraction because it never IS the real thing but only describe some of it’s aspects.
Models can have different form. Formulas in math, screenplay or scripts for a movie, descriptive text, and diagrams. In UML we have many model types. The trick is to choose the correct model type for the aspects you want to discover. Drawing can be done with a pencil and paper is willing, so you can easily become confused about syntax and semantics of the modeling language, in particular on what to use when.
A natural order of modeling, diagram wise, is something like this:
-
A sketch of the things involved, or a picture, which serves as an initial model. This is what you collect in an interview.
-
The UML equivalent is an Object diagram, in which you can simply draw 6 dogs if that is what fits in a kennel.
-
Or simplify it and draw 1 dog and and add 6 to say that you have six. It makes the model simpler and still have the same information.
-
You want to model relations between objects, like ownership or space to live. In an object diagram that is a line between objects, and as far as dogs and owner goes the 'direction' of the line goes both ways, because 'you know your boss, don’t you George?'.
-
Drawing many owners and dogs becomes tedious, so you need another simplification to leave details out. This gets you to an entity relation diagram or domain model. The diagram does what the name implies: objects and their associations. So one icon to represent dog and owner plus the connecting line suffices. Add multiplicites to express that an owner can have multiple dogs, but no less than one, less he/she not be an owner. As far as the dog is concerned there is only one real pack leader at any time. The graphical syntax you use (lines and boxes) can look a lot like an object diagram. The relevant details are in the relations and multiplicities or cardinalities at the ends.
-
A next abstraction is wanting to reason about types a.k.a. classes in UML. The class diagram actually has the wrong name, it should have been called the type diagram. Its purpose is to find the relations between types, who uses whom or who determines what. It is about dependencies and further abstraction. For instance, both a dog and child should be able to listen, so they have a commonality you want to express, like
Obeyorwhich is not a word but expresses what you want the sub-types to do. It does not change dog nor child but extracts the detail you want to reason about.
Modeling serves to highlight the important aspects. Choose the proper kind of diagram and try to closely stick to the syntax and semantics of the diagram and its purpose, so it helps the understanding of the details you DO want to communicate.
Modeling is always about leaving out details. Making things simpler.
Do not add details to a diagram that make no sense.
To paraphrase someone famous Everything should be made as simple as possible, but no simpler.
The above implies that the situation is not black or white, but some shade of gray.
That grayness is the reason of the confusion, because there is not one answer that fits in all situations.
It also means that you do not have to draw all diagrams all of the time, but only the diagrams that are needed. The question of
course is: How do you know that it is needed? The answer is: as soon as you want to discover or explain something.
Discovering is explaining to yourself. In a course where you need to learn the syntax and semantics of a language you must
of course practice it and use the "words" (icons, lines) to form proper sentences (models, diagrams).
A model is a kind of plan and help to keep oversight, both overall and in the details, where required.
Let me explain:
First you should consider the purpose of the diagram.
-
If you want to play out a scenario, you need objects (instances), and a box and line or stick model actors suffices. Boxes often will do because they are easily drawn (simplification).
-
Object diagram could be the next step.
Then
-
If it is about data analysis, a.k.a. domain modeling, relations between entities, then multiplicities DO matter.
-
A domain model show the relations between data elements. These relations often go two ways, and is natural, hence there is no prevalent direction.
-
If it is about designing your system architecture, then the directions of the associations (is-A, uses, or has-A) take precedence.
-
A proper class diagram of a software system is a directed graph. The relations need to have a direction, so you can discover what should or can go where, or can’t. The directions are especially important because in dependencies (which is what these arrows show), you are not allowed to have cycles.

-
In a software system class diagram, that serves to find potential reuse (using an already existing idea or type etc), cardinalities have no meaning.
-
Its suffices to know the types (class, interface) and their relation, and you rarely need to specify how many instances you will have.
-
If you do need to specify a number, then typically enum is the solution, which implicitly also serves as Singleton.
-
Let us use metaphores. Sausage and Sausage Machines.
-
A domain model is about the data. It is about sausage.
-
In the domain you specify what proportions of meat, fat, spicing, and skin you use. This is called the recipe. The processing takes place in machines.
-
-
A system design is about the sausage machines.
-
What type of bolts and nuts do we need. What is the type of steel for the grinder, and what is it’s shape etc. You need only one design ( ==template, class ) of each.
-
The size (diameter) and consistency of the sausage matter, but for the rest it is metal, wood, plastic, rubber etc.
-
The temperature and preparation time of course also matter, but that is how you use the machine.
-
-
The assembly process of the machine is the last part as far as producing machines goes.
-
In the assembly you need to know the number of bolts, grinder wheels etc. Meat nor sausage is involved, unless you hit yourselves with a spanner. The sausages will be involved in the test lab. (Think test scenarios). Compare the assembly process of the meat grinder to what a compiler does to a program. As far as the compiler is concerned, the program’s source code is just data. And so are the components of the meat grinder during assembly. During use it becomes (part of) the system.
-
You will find places where counts matter, like a GUI that shows items of a varying number.
But than also, that count comes from the data. (Show the customers in a GUI list). -
In all other cases the GUI widgets will have names. These names can be applied to the system components. Those are specialized by for instance inheritance or composition but also by configuration, like the colour of the handle of the meat grinder or the text on a label. Or even applying plugins like in a meat grinder by replacing the grind wheel and extruder to get a different sausage type.
-
Transformation of the domain model into the system class diagram sounds reasonable,
but is in fact a fallacy._
It would be as if you could turn sausage into a sausage machine. I’m pretty sure your Butcher will tell you different when you would propose such a solution.

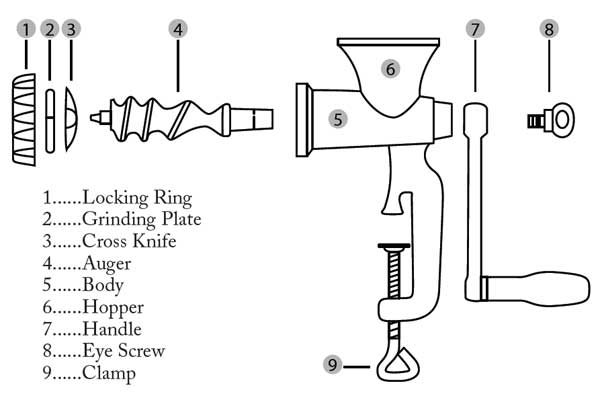
Quiz: What UML diagram type describes the images above best?
The sausages come close to an object diagram. Not much details is shown, which is proper for sausages. You do not want to known. The model is there to express yummy none-the-less.
The meat grinder picture is actually also an object diagram, it is the model to be used for assembly. It does have type names though, and luckily for my case only uses one of each. Ikea build plans are different.
Lucy, where is that Alan-wrench?
Sometimes it helps to go from the meta level to metaphors, to explain things, because \(\text{meta} = \text{abstract}^2\).
Do so if you have to explain something, but once the abstraction has been understood by the reader, you can stop simplifying.
It is easier to model sausages than dogs, because the former sit still.
That concludes this intermezzo on currywurst.
Pieter van den Hombergh, March 2021.
1. Java DataBase Connectivity
1.1. DataBase connection credentials and Java Properties.
Some things do NOT belong in source code. In particular do not put credentials of any kind inside files that are committed to a version control system, such as source code. Make sure you configure your version control system such that such files are excluded from commits.
Instead put credentials in separate files, that are easily understood by both a human that uses it
to configure access to a resource, and also by the programming language.
In java the tradition is to use so called properties files, which, also traditionally, have a file extension .properties.
It also helps to give such files well known names, so the program can refer to them by that name.
For the demonstrations in this part we will use the following properties file.
# You can add comments here.
jdbc.pg.dev.dbname=dev
jdbc.pg.dev.username=exam
jdbc.pg.dev.password=exam
jdbc.pg.dev.hostname=localhost
jdbc.pg.prod.dbname=prod
jdbc.pg.prod.username=appdbuser
jdbc.pg.prod.password=verySecretPassw00rd
jdbc.pg.prod.hostname=dbclusterYou can see that the properties file supports two environments, development and production.
static DataSource getDataSource( final String sourceName ) {
// dataSourceByName is a map, serving as a cache.
return datasourceByName.computeIfAbsent( sourceName,
( s ) -> {
Properties props = properties( "application.properties" );
PGSimpleDataSource source = new PGSimpleDataSource();
String prefix = sourceName + "."; (1)
String[] serverNames = {
props.getProperty( prefix + "dbhost" )
};
source.setServerNames( serverNames );
String user = props.getProperty( prefix + "username" );
source.setUser( user );
source.setDatabaseName( props.getProperty( prefix + "dbname" ) );
source.setPassword( props
.getProperty( prefix + "password" ) );
String pingQuery = "SELECT current_database(), now()::TIMESTAMP as now;";
try ( Connection con = source.getConnection();
// ping the database for success.
PreparedStatement pst = con.prepareStatement( pingQuery ); ) {
try ( ResultSet rs = pst.executeQuery(); ) {
if ( rs.next() ) {
Object db = rs.getObject( "current_database");
Object now = rs.getObject( "now");
System.out.println("connected to db "+ db.toString()+ ", date/time is " + now.toString() );
}
}
} catch ( SQLException ex ) {
Logger.getLogger( PgJDBCUtils.class.getName() ).log( Level.SEVERE, null, ex );
}
return source;
}
); // end of lambda.
}
// read properties
static Properties properties( String propFileName ) {
Properties properties = new Properties();
try (
FileInputStream fis = new FileInputStream( propFileName ); ) {
properties.load( fis );
} catch ( IOException ignored ) {
Logger.getLogger( PgJDBCUtils.class.getName() ).log(
Level.INFO,
"attempt to read file from well known location failed'",
ignored );
}
return properties;
}| 1 | The sourceName is the key or namespace from where to pickup the connection details. Simple and effective. |
1.2. Using a Data source
There are some traditional ways to obtain a database connection. We use a DataSource, which itself
can be seen as a resource, similar to a service in the architecture diagram of the testable design.
The data source can then be used to obtain a connection. In the example you see a class that needs a DataSource
that is provided at construction time of the class, so it is available when the instance is created.
A connection is AutoClosable so candidate for try-with-resources.
package simplejdbc;
import java.sql.Connection;
import java.sql.SQLException;
import javax.sql.DataSource;
/**
*
* @author hom
*/
public class DataSourceDemo {
final DataSource datasource; (1)
public DataSourceDemo( DataSource datasource ) { (2)
this.datasource = datasource;
}
void demo() throws SQLException { (3)
String query (4)
= """
select state.name as state,p.name as president,state.year_entered
from president p join state state on(p.state_id_born=state.id)
where state.name like 'N%'
""";
doQuery( query, System.out );
}
}| 1 | Resource used in methods of this class. |
| 2 | Constructor receives the DataSource. |
| 3 | The method uses the DataSource to get a connection in the try-with-resources block and passes it on to the method that executes the query and deals with the result by printing it. |
| 4 | text blocks, since java 14, combine nicely with sql queries. |
The doQuery(…) method uses the supplied connection to create a statement which is then executed to produce a ResultSet.
You will see some similarities in what you have seen in project 1, using php PDO.
void doQuery( String query,
PrintStream out ) throws SQLException {
try ( Connection con = datasource.getConnection();
Statement st = con.createStatement();
ResultSet rs = st.executeQuery( query ) ) {
new ResultSetPrinter( rs ).printTable( out );
}
}The ResultSetPrinter tries to make a nice looking table of the result of the query. You can imagine that this is a bit of code, but that is not relevant for this demo of JDBC.
1.3. ResultSet
For all queries that return a tabular result, the first JDBC class
you will use is the ResultSet.
The ResultSet also provides so called Meta Information that describes the types of the values
in the columns, the number of columns, display size etc.
This can be used to:
-
produce a nice tabular format
-
by using a translation or mapping between the database types and Java types, how the column data is to be used, type wise.
1.4. Anatomy of a prepared statement
In the example earlier, the sql text used to create the statement is constant, because it needs no user input. If a statement does, you should always use a PreparedStatement.
In the JDBC standard you fill in the parameters from the user in multiple ways, but the simplest is to
just use question marks (?) as placeholders and specify which columns and column values
you want to insert or update, or you want to use in your select or delete query.
insert into students (student_id , lastname, firstname, dob, gender) (1)
values (? , ?, ?, ?, ?) (2)
returning * (3)| 1 | Fields can be supplied in any order, including definition order. |
| 2 | You do not need the spaces before the commas, I added them for readability. |
| 3 | It is smart to always expect back what has been inserted by the database, including generated id and
other fields such as the database’s notion of date or time. Even smarter, but a little more work
is to specify the columns instead of a *, so that the order in which you receive them is independent
of database schema organization and stable. |
|
Lots of problems can allegedly be solved with an extra level of Indirection. As an example: in programming there is the rule to not program against an implementation, but against an interface. With databases the indirection trick is: use views instead of tables. |
Now assume the SQL text contains the above. Also assume that we have an array of student data, simply as an array of objects.
Object[] studentData = {123513, "Klaassen", "Jan", "1993-05-12" , "M"}; (1)| 1 | The most likely source of this data a Student object deconstructed by a StudentMapper. |
Then creating the prepared statement and filling it with values is a simple loop:
try (
Connection con = datasource.getConnection();
PreparedStatement stmt = con.prepareStatement( query ); ) {
int count = 0;
for ( Object param : studentData ) {
stmt.setObject( ++count, param ); (1)
}
return stmt.executeUpdate();
}| 1 | note the pre-increment, so count starts with column 1. |
You see that this is quite simple and other than what is specified in the query, there is no extra need for data conversion or named column use.
|
Contrary to what the documentation suggests, you can almost always use setObject, because in the common case, what you put in is of the right type, as long as you keep the order of the parameter types intact. |
This approach can be used to make database access even simpler, so you only have to provide the data in an array and the rest can be packed into utility methods.
The holy grail is to find a way to do all kind of queries against tables, and the only thing you need to know is the table name and what entities as Java objects can be expected to be read from or written to the table.
We combine this with the ideas presented in part 3 about testable design, part 4, generics, and part 6, reflection. We are quite sure that the programming style from week 5, with lambda expressions and streams will also come handy.
We actually want to focus on testing the business code, with that business code to be oblivious of the actual persistence layer or service it uses to get the data, and avoid to write a lot of boiler plate code. As a replacement for the later we will introduce the DAO concept.
2. Traditional preparing statements
In tests you should use traditional approaches, instead of the mechanisms your
are testing. The code below illustrates what that means.
It is used by code that tests the bank transfer service implemented in the database. This example
is filling the account tables from some List of accounts.
static String addAccount = "insert into account(accountid,balance,maxdebit,customerid,astate) "
+ "values(?,?,?,?,?)";
static void loadAccounts() throws SQLException {
try ( Connection con = olifantysSource.getConnection();
PreparedStatement pst = con.prepareStatement( addAccount ) ) {
for ( Account account : accounts ) {
pst.setObject( 1, account.accountid );
pst.setBigDecimal( 2, account.balance );
pst.setBigDecimal( 3, account.maxdebit );
pst.setObject( 4, account.customerid );
pst.setString( 5, account.astate );
pst.addBatch(); (1)
}
int[] results = pst.executeBatch();
System.out.println( "results = " + Arrays.toString( results ) );
} catch ( PSQLException e ) {
System.out.println( "caused by " + e.getNextException() );
throw e;
}
}| 1 | We do multiple inserts in one batch. Auto commit is off. The try-with-resources block takes care of the jdbc transaction. |
3. Database Meta Information
DO Mention the metadata…
In the previous part we have seen how to use reflection on java classes.
A similar and standardized concept also exists for databases. You can retrieve all kind
of meta information about the objects (such as tables and views) defined in your database.
Accessing that data can be done with selecting data from special relations in a special schema,
called the information_schema.
Suppose we have the following definition of a table students in the schema public:
CREATE TABLE public.students (
student_id INTEGER PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, (1)
firstname TEXT NOT NULL, (2)
lastname TEXT NOT NULL,
dob DATE NOT NULL,
cohort integer NOT NULL DEFAULT EXTRACT('year' from now()), (3)
email TEXT NOT NULL,
gender CHARACTER(1) NOT NULL check (gender in ('F','M','U')), (4)
student_grp TEXT NOT NULL,
active BOOLEAN DEFAULT false NOT NULL
);| 1 | ISO SQL for a serial column that by default is generated, and also is primary key. |
| 2 | All columns that 'traditionally' would be varchar are now text. Just as efficient less hassle. It will always fit. Only use varchar if your business requires a length constraint. |
| 3 | The cohort is the year of registration, which can be derived from the insertion moment. |
| 4 | Gender is a one character value with a restricted value set, much like an enum, but simpler. |
If after the definition your would ask the database what it knows about this table with
SELECT ordinal_position, column_name,data_type, column_default, is_nullable,
is_generated, datetime_precision
FROM information_schema.columns WHERE table_name ='students' ORDER BY 1;you would get the following as output:
┌──────────────────┬─────────────┬───────────┬──────────────────────────┬─────────────┬──────────────┬────────────────────┐
│ ordinal_position │ column_name │ data_type │ column_default │ is_nullable │ is_generated │ datetime_precision │
╞══════════════════╪═════════════╪═══════════╪══════════════════════════╪═════════════╪══════════════╪════════════════════╡
│ 1 │ student_id │ integer │ │ NO │ NEVER │ │
│ 2 │ firstname │ text │ │ NO │ NEVER │ │
│ 3 │ lastname │ text │ │ NO │ NEVER │ │
│ 4 │ dob │ date │ │ NO │ NEVER │ 0 │
│ 5 │ cohort │ integer │ EXTRACT(year FROM now()) │ NO │ NEVER │ │
│ 6 │ email │ text │ │ NO │ NEVER │ │
│ 7 │ gender │ character │ │ NO │ NEVER │ │
│ 8 │ student_grp │ text │ │ NO │ NEVER │ │
│ 9 │ active │ boolean │ false │ NO │ NEVER │ │
└──────────────────┴─────────────┴───────────┴──────────────────────────┴─────────────┴──────────────┴────────────────────┘From this information you can imagine that it is relatively easy to generate the matching Java types as record type.
The resulting record would look like this:
package entities;
import java.time.LocalDate;
public record Student (
int student_id,
String firstname,
String lastname,
LocalDate dob,
int cohort,
String email,
char gender,
String student_grp,
bool active
){} (1)| 1 | indeed, no body whatsoever. |
|
If your columns are nullable, choose a type that also 'accepts' null values, so in that case use a ref type, such as Integer or Boolean. If the columns in the table are declared as non-nullable you can use primitive types. |
Because in the Java layer you would like to have the meta information handy in a Mapper, you can generate the mapper at the same time from the database information instead of using reflection to the same effect. You teachers might turn that into an exercise.
3.1. Check constraints
Similarly you can also get the information of the check constraints with another, a bit more involved query.
-- retrieve the check constraints for the user schemas
select tc.table_schema,
tc.table_name,
string_agg(col.column_name, ', ') as columns,
tc.constraint_name,
cc.check_clause
from information_schema.table_constraints tc
join information_schema.check_constraints cc
on tc.constraint_schema = cc.constraint_schema
and tc.constraint_name = cc.constraint_name
join pg_namespace nsp on nsp.nspname = cc.constraint_schema
join pg_constraint pgc on pgc.conname = cc.constraint_name
and pgc.connamespace = nsp.oid
and pgc.contype = 'c'
join information_schema.columns col
on col.table_schema = tc.table_schema
and col.table_name = tc.table_name
and col.ordinal_position = ANY(pgc.conkey)
where tc.constraint_schema not in('pg_catalog', 'information_schema')
group by tc.table_schema,
tc.table_name,
tc.constraint_name,
cc.check_clause
order by tc.table_schema,
tc.table_name;which, because only one column in this schema actually declares a check constraint, results in:
┌──────────────┬────────────┬─────────┬───────────────────────┬─────────────────────────────────────────────────────────────────┐
│ table_schema │ table_name │ columns │ constraint_name │ check_clause │
╞══════════════╪════════════╪═════════╪═══════════════════════╪═════════════════════════════════════════════════════════════════╡
│ public │ students │ gender │ students_gender_check │ ((gender = ANY (ARRAY['F'::bpchar, 'M'::bpchar, 'U'::bpchar]))) │
└──────────────┴────────────┴─────────┴───────────────────────┴─────────────────────────────────────────────────────────────────┘You can use the check constraints in your business code too, but actually deferring those checks as final checks to the database is just fine. The database layer with throw an appropriate exception when a value is not to the liking of a constraint.
You may want to use the check information in the user interface layer, to warn the user that a transaction will not succeed with a illegal or missing value. Parsing the check clause is of course a bit complex, but with a regex you can do a lot, and also know that most check constraint are relatively simple.
4. Transactions
Things that can go wrong will go wrong. This problem is aggravated by having to use multiple things. Murphy says hello again.
A transaction is defined as a sequence of operations that can either succeed completely or be undone
without any residual effect.
In plain English: It either happens fully, or we can forget about it.
For a persistence layer that means: if it cannot fulfill the obligation it should make sure that nothing happens to compromise the data already stored before the transaction.
The simple explanation of how this works is that the party that is busy with a resource gets the resource all for itself, locking any other parties out. If something fails, the mess created can either be undone (rollback) or not committed, which in effect is the same.
 Locking out sounds serious, and it is, on multiple accounts.
Locking out sounds serious, and it is, on multiple accounts.
-
When using a BIG lock, as locking out all other parties, things become VERY slow.
-
When lock less, like just a table, or better still, only the records we want to modify, then DEADlocks can occur, which is even more problematic than having to wait.
-
In all cases, when something goes awry, one may have to clean up mess in multiple places.
All this can be related to quite difficult problems. Luckily there are solutions to that and, not unimportant, as far as the database goes, that can typically deal with the issues pretty well.
The hello world of transactions is transferring money between bank accounts.
In this simplest case the bank records live in the same table.
The essential operation involves at least two database records, one to debit (take from) and the other to credit(add to).
To modify a record without anyone interfering, you have to lock it. So you need two locks, one for each records.
You can only request locks in sequence, one after the other.
Now assume that other transactions are taking place at the same time, all updating the same table.
|
If something is difficult, see if you can find a solution that does the job, maybe even better. In the solution below we choose to delegate the deadlock avoidance to a (set of) stored procedures inside the database. This simplifies the design and implementation of the Java layer, is probably more reliable and makes less work for us the Java programmers, which always is cool. But be warned that someone has to test and implement the stored procedure. And if you aspire to become a 'FULL STACK' developer, that could be you too. |
5. Using Stored Procedures
As promised in the tip, we delegate the transactional responsibility to the database, so calling it is relatively simple.
First the top level code in the proper clean code order.
Calling the code is actually quite simple, it is like calling a prepared statement with a select that invokes the stored procedure.
static long FROM_ACCOUNT= 100;
static long TO_ACCOUNT= 110;
@Test
public void transferOK() throws SQLException {
try ( Connection con = dataSource.getConnection(); ) {
con.setAutoCommit( false );
Account pre = findAccount( con, TO_ACCOUNT );
long transactionId= doQuery( con, (1)
System.out, (2)
"select transferlockfree(?,?,?,'should be ok')", (3)
FROM_ACCOUNT, TO_ACCOUNT,110,25 ); (4)
Account post = findAccount( con, TO_ACCOUNT );
assertThat( post.balance )
.as("transaction failed")
.isEqualTo( pre.balance.add( new BigDecimal( "25" ) ) );
con.rollback(); // this is a test, leave the account in pristine state.
}
}| 1 | Implementing doQuery is left as an exercise. |
| 2 | log output to system out |
| 3 | query text |
| 4 | query params |
A psql script that does the above can be found under the link bankingactions.sql
The pgplsql code in the link above avoids deadlocks by using the account records in a fixed from low to high order.
|
Although this website is about Java programming, mastering database programming on the database level is a skill that belongs in the skill-set of a full stack developer or architect. |
6. The TAO of DAO.
The Data Access Object (DAO) pattern provides an abstraction to the business logic that hides and thus decouples persistence from the business logic. When done right, one DAO implementation can be replaced with another one, for instance for the purpose of testing (with a mocked DAO), speed (with an in-memory DAO) or different service, for instance by replacing the relational database with a (remote) rest service.
Lets first start with a example of why one would like to use a DAO.
In the CSV to Objects exercise we saw that it’s possible to use
CSV files to store and retrieve Students.
Files can be used for this purpose, however it’s not always the best solution.
For example if we want to make sure values are of the correct type,
model relationships between different objects or
make sure that certain values are unique.
For this level of control we can use a Relation Database Management System (RDBMS).
So imagine that we want to use the database to store and retrieve Students,
as done in the CSV to Objects exercise.
The Student class itself is of course not responsible for anything to do with the database.
So we need a class that is specifically for database interaction for Students.
For example a StudentDAO. This StudentDAO contains methods to save, get, update and delete Students. For example the update method could look as follows:
public Optional<Student> update(Student student){
String query =
"update students set (lastname, firstname, email)"(1)
+ "= (?, ?, ?) "(2)
+ "where snummer=?"(3)
+ "returning lastname, firstname, email";(4)
try(Connection con = dataSource.getConnection();){
try(PreparedStatement pst = con.prepareStatement(query)){(5)
pst.setString(1, student.getLastname());(6)
pst.setString(2, student.getFirstname());
pst.setString(3, student.getEmail());
pst.setInt(4, student.getSnummer());
try (ResultSet rs = pst.executeQuery();) {(7)
if ( rs.next() ) {(8)
return Optional.ofNullable( recordToEntity( rs ) );(9)
} else {
return Optional.empty();
}
}
}
} catch (SQLException ex) {
Logger.getLogger(StudentDAO.class.getName()).log(Level.SEVERE, null, ex);
throw new RuntimeException(ex.getMessage(), ex);
}
}| 1 | Specify all the names of student fields |
| 2 | Specify the correct number of placeholders |
| 3 | Specify which student record to update |
| 4 | Specify the values we want back from the database |
| 5 | Prepare the statement (send it to the database) |
| 6 | Set all the required values |
| 7 | Execute the query |
| 8 | Check if the ResultSet contains values (rows) |
| 9 | Convert the ResultSet back to an entity (including snummer) |
String query =
"""
update students set (lastname, firstname, email) = (?, ?, ?)
where snummer=?
returning lastname, firstname, email
""";One of the problems with this approach is that the StudentDAO has to be
updated if the Student entity changes. E.g. if we add a new field to Student
or change the name of an existing field we have to update the StudentDAO.
Thankfully in the previous week we created a GenericMapper. This GenericMapper
has exactly the functionality that we need to generate the
query and the PreparedStatement.
StudentMapperpublic Optional<Student> update(Student student){
var studentMapper = Mapper.mapperFor(Student.class);
var columnNames = studentMapper.entityFields()(1)
.stream()
.map( Field::getName )(2)
.collect( toList() );
String columns = String
.join( ",", columnNames );(3)
String placeholders = makePlaceHolders( columnNames.size() );(4)
String query = format(
"""
update %1$s set (%2$s)=(%3$s) where (%4$s)=(?)
returning %2$s
""",
"students",
columns,
placeholders,
mapper.getKeyFieldName() );
try(Connection con = dataSource.getConnection();){
try(PreparedStatement pst = con.prepareStatement(query)){
fillPreparedStatement(pst, student);(5)
try (ResultSet rs = pst.executeQuery();) {
if ( rs.next() ) {
return Optional.ofNullable( recordToEntity( rs ) );
} else {
return Optional.empty();
}
}
}
} catch (SQLException ex) {
Logger.getLogger(StudentDAO.class.getName()).log(Level.SEVERE, null, ex);
throw new RuntimeException(ex.getMessage(), ex);
}
}| 1 | Retrieve all the fields of Student |
| 2 | Map the fields to their names |
| 3 | Join the column names |
| 4 | Helper function that creates a string containing the placeholders |
| 5 | Fill the PreparedStatement with the values from Student using the StudentMapper.deconstruct(student) |
By doing it this way, we don’t have to update the StudentDAO if the Student
is changed (we can auto-generate the new StudentMapper instead).
This now works for the Student class, but of course we need this functionality
for more entities, e.g. Lecturer, Course, etc. We can do that by making our StudentDAO generic. In the previous weeks we have seen how to convert an implementation
for a specific type to a generic base implementation. By following the same steps
we can come to the following generic DAO.
public interface DAO<E, K> extends AutoCloseable{(1)
Optional<E> update( E e );
....(2)
}| 1 | Where E is the type of the entity (e.g. Student) and K is the type of the
primary key (e.g. Integer) |
| 2 | Removed additional methods for brevity |
DAO<Employee,Integer> sdao = daoFactory.createDao( Student.class );
Student j = sdao.save( new Student(....) ).get(); (1)
| 1 | The return value of the save operation is an Optional<Student>. If present
the student object contains the exact same values as the record in the database, primary key and generated field and all the rest. |
|
A DAO is a use-once object. So you get a DAO, use and then discard it (let the garbage collector take care of it). If you need to work on more than one entity, you should get a transaction token, that can then be used to commit or rollback the operation. |
try (
DAO<Department, Integer> ddao = daof.createDao( Department.class ); (1)
TransactionToken tok = ddao.startTransaction(); (2)
DAO<Employee,Integer> edao = daof.createDao( Employee.class, tok ); ) { (3)
savedDept = ddao.save( engineering );
int depno = savedDept.getDepartmentid();
dilbert.setDepartmentid( depno );
savedDilbert = edao.save( dilbert );
System.out.println( "savedDilbert = " + savedDilbert );
tok.commit(); (4)
} catch ( Exception ex ) {
ttok.rollback(); (5)
Logger.getLogger( TransactionTest.class.getName() ).
log( Level.SEVERE, null, ex );
}| 1 | Create a Dao, |
| 2 | and have it make a token for all other daos involved in this transaction to use |
| 3 | as here with the edao. |
| 4 | If this point is reached we have success and commit, |
| 5 | otherwise any exception from the try-block above leads us here and we abort the transaction, thereby undoing everything that might have happened, database wise. |

Now we can use this generic DAO to create a StudentDAO, CourseDAO, etc.
The implementing class of a DAO needs to retrieve the correct mapper for the entity type.
Thankfully that was also already implemented in last weeks exercise.
final Mapper<Student, Integer> mapper = Mapper.mapperFor(Student.class );The are only two changes needed to make the update method from the non-generic StudentDAO work.
-
Retrieve the correct mapper based on the generic type.
-
Auto-generate the table name from the generic type
And now we have a generic DAO that can update entities in the database.
And now back to the theory.
A DAO is defined as an interface, and the implementations can be generated by a factory and are reused when registered in a registry. A lot like the things we saw in week 6.
// K is id, E is entity
interface DAO<K,E> extends AutoClosable {
Optional<E> get( K id );
List<E> getAll();
default List<E> getByColumnValues( Object... keyValues );
Optional<E> save( E e );
E update( E e );
void deleteEntity( E e );
void deleteById( K k );
default TransactionToken startTransaction();
default DAO<E, K> setTransactionToken( TransactionToken tok );
default TransactionToken getTransactionToken();
default int size();
default int lastId();
default void close() throws Exception;
default List<? extends E> saveAll( List<E> entities );
default List<? extends E> saveAll( E... entities );
default void deleteAll( Iterable<E> entities );
default void deleteAll( E... entities );
default List<E> anyQuery( String queryText, Object... params );
}A database specific DAO may have extra methods.

In the class diagram you see that the DAO can have multiple realizations:
-
In memory: The DAO is simply keeping the data in memory, typically in lists or maps.
-
RDBMS: Like a PostgreSQL based implementation, or even one that is database dialect agnostic.
-
REST: A DAO that uses rest service(s) do provide its service.
In all cases, the business logic knows a DAO factory to get a DAO, but does NOT need to know the implementation. The better you stick to rule of low coupling, that is let the business logic know as little as possible about the implementation, the better the business logic is portable to a world with different service implementations. For instance, the same business logic would be able to run on top of or talk to a backing RDBMS database, a rest service, a no-SQL database or a file-system.
To make this work, the service should be rich enough, to avoid the need for the circumvention of the abstract definitions.
One could imagine to define an abstract expression language that can express things like 'give me all contracts that expire before a specific date',
including means to combine these mostly boolean expressions.
But that would be an exercise for another day.
Lets get our hands dirty implementing a DAO using PostgreSQL as the supported database.
6.1. Update
We will now take a look at how the update method is implemented in the PGDAO.
E update( E t );, We get an object E and should update the correct row
in the database, based on the primary key.
The SQL statement for that is basically update tablename set (col1, col2) = (val1, val2)
where idcolumn=?.
But we want more control, because we want to get column values in the order of the entity
so we can create an entity instance of it using the mapper.
We can ask the same mapper for the field order.
So in terms of Student: update students set (firstname,… active,),
with all defined field names in between.
The DAO code, from top (near the user of the method) to the bottom (implementation details).
final Mapper<E, K> mapper;(1)
PGDAO( PGDAOFactory fac, DataSource ds, Class<E> entityType,
QueryFactory queryTextCache, AbstractQueryExecutor qe ) {
this.mapper = Mapper.mapperFor( entityType );(2)
....(3)
}| 1 | The Mapper<E,K> used by DAO<K,E> is as abstract (that is in terms of E) as the dao. |
| 2 | Get the mapper for the entity type |
| 3 | Rest of the constructor left out for brevity |
@Override
public E update( E t ) {
if ( null != transactionToken ) {(1)
return update( transactionToken.getConnection(), t );
}
try ( Connection con = this.getConnection(); ) {(2)
return update( con, t );(3)
} catch ( SQLException ex ) { // cannot test cover this, unless connection breaks mid-air
Logger.getLogger( PGDAO.class.getName() ).log( Level.SEVERE,
ex.getMessage() );
throw new DAOException( ex.getMessage(), ex );
}
}| 1 | In case of a pending transaction, there is a token. Use the token’s transaction. |
| 2 | Get the connection in a try-with-resources block and do it all by yourself. |
| 3 | And do the work in the method E update(con, id); |
So what does the update helper method do?
private E update( final Connection c, E e ) {
String sql = queryFactory.updateQueryText();(1)
K key = mapper.keyExtractor().apply( e );(2)
return (E) qe.doUpdate( c, sql, e, key );(3)
}| 1 | Retrieve the actual query text (update tablename set ….) |
| 2 | Retrieve the primary key |
| 3 | Execute the actual update |
We will have a look at the updateQueryText method in the exercise of this week, so for
now let us focus on the doUpdate.
@Override
E doUpdate( final Connection c, String sql, E e, K key ) throws DAOException {
try ( PreparedStatement pst = c.prepareStatement( sql ); ) {
Object[] parts = mapper.deconstruct( e );
int j = 1;
// all fields
for ( Object part : parts ) {
if ( part == null ) { (1)
pst.setObject( j++, part );
continue;
}
Object po = factory.marshallOut( part ); (2)
if ( po instanceof PGobject ) {
pst.setObject( j++, part, java.sql.Types.OTHER ); (3)
} else {
pst.setObject( j++, part ); (4)
}
}
pst.setObject( j, key ); (5)
try ( ResultSet rs = pst.executeQuery(); ) {
if ( rs.next() ) {
return (E) recordToEntity( rs ); (6)
} else {
return null;
}
}
} catch ( SQLException ex ) {
Logger.getLogger( PGDAO.class.getName() ).log( Level.SEVERE, null,
ex );
throw new DAOException( ex.getMessage(), ex );
}
}| 1 | null needs no conversion. |
| 2 | Do required type conversions. The dao factory is specific to a database dialect. You should not do this in the mapper, because that would bind the mapper to a database. |
| 3 | So called PGobjects get special treatment. Needed for none-standard JDBC types such as TIMERANGES |
| 4 | Walk through all columns in the PreparedStatement. |
| 5 | Put the key value at the place of the last ?. |
| 6 | We know this guy. |
Not lets have a quick look at how to convert a record from the ResultSet to an instance
of the entity type.
ResultSet to an instance of entity type@Override
E recordToEntity( final ResultSet rs ) throws SQLException {
Object[] parts = new Object[ mapper.getArraySize() ]; (1)
for ( int i = 0; i < parts.length; i++ ) {
Class<?> type = mapper.entityFields().get( i ).getType();(2)
parts[i] = factory.marshallIn( type, rs.getObject( i + 1 ) );(3)
}
return mapper.construct( parts );(4)
}| 1 | Create an array that will hold all the entity fields |
| 2 | Get the type of the entity field |
| 3 | Convert the object from the record to the correct field type |
| 4 | Construct a new entity instance |
Now we know how the PGDAO update works, except for the updateQueryText.
This part will be discussed in the following exercise.
Exercise Generic DAO
Generic DAO
To make your part better testable we introduced a few helper types.

-
Refactoring out the execution of the queries to the actual database and introducing the interface allows you to mock the AbstractqueryExecutor. The default implementation is given, and can be left as is.
The other class is the QueryFactory, which both computes AND caches the queries that are specific for an operation and entity type.
In this exercise you will work with the genericdao project.
The layout of the project is as described in the class diagram.
The task is to test and implement the QueryFactory class.
-
The project you get is a complete DAO implementation with the tests and implementations for the QueryFactory for you to complete. Look for the TODOs (in netbeans ctrl+6).
-
An actual database will not be needed by your tests. However, if you would like to experiment with that, you need the have an
application.propertiesfile in the root of your directory. There is a template for that file to start with, but do not commit the applications.properties file.
| If you are only testing your own work, remove the application.properties file, so you do not enable the database tests. In that case the tests take about 3 seconds to run; with the database tests active, if takes 25 seconds on a fast machine. |
For every operation there are two goals: . Write/complete the test to assert that the query contains the required parts such as the sql command, column names, the placeholders (?,?,?,?,?,?) and table name. . In the implementation .. Generate the correct query string .. Cache the calculated query string for future use.
Lets have a look at the QueryFactory and especially the updateQueryText.
QueryFactoryfinal Mapper<?, ?> mapper;(1)
ConcurrentMap<String, String> queryTextCache = new ConcurrentHashMap<>();(2)
public QueryFactory( Mapper<?, ?> mapper ) {
this.mapper = mapper;(3)
}| 1 | We need a mapper to be able to create the correct query strings |
| 2 | Cache so we don’t need to recompute the query string every time |
| 3 | Save the correct mapper for this entity type |
String updateQueryText() {
return queryTextCache
.computeIfAbsent( "update", x -> computeUpdateQueryText() (1)
);
}| 1 | Check if "update" is already in the cache, if not compute the update query text |
So now we get to the actual computation of the update query string.
private String computeUpdateQueryText() {
var columnNames = mapper.entityFields()(1)
.stream()
.map( Field::getName )(2)
.collect( toList() );
String columns = String
.join( ",", columnNames );
String placeholders = makePlaceHolders( columnNames.size() );(3)
String sqlt = format(
"update %1$s set (%2$s)=(%3$s) where (%4$s)=(?)"
+ " returning %2$s",
tableName(),
columns,
placeholders,
mapper.getKeyFieldName() );(4)
return sqlt;
}| 1 | Get all the entity fields |
| 2 | Map the fields to their respective names |
| 3 | Helper method to create a string containing the number of placeholders |
| 4 | Get the key field |
And finally have a look at the makePlaceHolders helper method.
final String makePlaceHolders( final int count ) {
String[] qm = new String[ count ];
Arrays.fill( qm, "?" );
return String.join( ",", qm );
}Now your task is to do the same for the other methods in QueryFactory.
Test driven of course, so first complete the test and then implement.
7. Testing databases
Your database design is an essential part of your application architecture. Using a database properly, as in declaring constraints and let the database decide what is acceptable constraint wise is the way to go.
When you declare a constraint, the database will raise (sql terminology for throw) an exception,
that is delivered to the java client as an SQLException or a subclass thereof. The SQLException will contain all
the relevant information for either the programmer (syntax problem in the statement)
or the program’s user because the input is not acceptable.
|
Client side validation is no substitute for proper database checks. Client side validation is at best an improvement to the user experience, because the client software can help prevent problems further down (after submitting the form) the line. |
7.1. Transactions
Often the interaction with the database involves the update of or insert into more then one record in one or more tables. Each of these operations may cause a constraint violation, meaning that the operation is not accepted. This will cause an exception.
When you have such a scenario, we call that a transaction. A transaction in databases means: It either completes successfully or not at all.
The setup typically is
try (Connection co= datasource.getConnection) {
} catch(SQLException sqe) {
co.rollback();
}8. Data First or Objects first?
You have seen in part 6 that you can retreive information about
objects and that you can even derive code from that.
The same applies to the database. You can retrieve information
from the data base objects (tables, views) and use that to 'reflect' on it,
for instance, as has been shown, to get type and names of columns.
There are two approaches
-
Objects First.
-
Data (database) first.
8.1. Objects First.
Objects is the approach you use when the design in the programming language is leading. You can use all the features of object orientation, and may have to bend the OO-rules a bit to fit stuff into the database. As an example for the less than perfect match: There is no real (usable) inheritance in the database, so the best you can do is join tables to go from person to teacher-attributes to teacher. The teacher is then a view. (How exactly is left as an exercise). The example below shows some design and implementation details for Students.
-
You create you entities in Java first.
-
With reflection you code mappers and table definitions.
8.2. Database First.
You define your data in tables and views first and use 'reflection' on it’s metadate to derive your entity types. Generating entities and entity mappers, which you still need, can be very easy, certainly with either project lombok, or the modern java record like in Java 14+.
At the time of writing, one must be a bit carefull. Not everything works with Java 16. It is particularly annoying that the maven surefire plugin refuses to work with java 16 byte-codes. That should not be an excuse for dropping tests.

Quiz: The devil is in the details. What relation is the Student Object representing?
The Student object are actually records from the students_v VIEW, which can be defined as
CREATE OR REPLACE VIEW students_v AS
SELECT person.name,person.dob,student.* (1)
FROM students_t natural join persons_t| 1 | It would be better to also name the columns you want to have, so you have a stable view, even after re-defining it. |
8.3. What is best?
Rule one
In all cases, keep the objects you transfer stupid. Apply the KISS principle.
-
In legacy systems, the legacy will decide the way forward, but you can use the techniques described to improve stuff. Either way.
-
In green field project you can go either way, or even mix and match. As long as what you communicate with your backing store is a simple data carrier, generating one format from the other is equivalent in both approaches, objects first or database first.
In all cases, you win, because when you have one definition you can transform it into the other. That works.
8.4. Proper Design Promotes Security.
In the picture above you can see that you can go to quite some lengths to keep secret data private.
For instance with the postgresql roles, rules, and row level security (\(R^3\)),
you could design a system in which no unneeded data is exposed to someone who does not need it,
and you could expose the secret data to its rightful owner like the real person, that is identified by the personid.
But that is a red tape area for other users.
It takes some work to get it done, but you see that can build to grade secure systems, only by cooking with water and sufficient expertise.
For those that do not stop at a TL;DR signs: An interesting read might be on PostgreSQL row level security
Study the JDBC Introduction.